
有些程序员在撰写数据库应用程序时,常专注于OOP及各种framework的使用,却忽略了基本的 SQL 语句及其「性能 (performance) 优化」问题。曾听过台湾某半导体大厂的新进程序员,所组出来的一段 PL/SQL 跑了好几分钟还跑不完;想当然,即使他的 AJAX 及 ooxx 框架用得再漂亮,系统性能也会让使用者无法忍受。以下是整理出的一些数据库规划、SQL performance tuning简单心得,让长年钻研 .NET、AJAX、一堆高深ooxx framework,却无暇研究SQL statement 的程序员,透过最短时间对本文的阅读,能避免踩到一些 SQL 的性能地雷。
1、数据库设计与规划
• Primary Key 字段的长度尽量小,能用small integer就不要用integer。例如员工数据表,若能用员工编号当主键,就不要用身分证号码。
• 一般字段亦同。若该数据表要存放的数据不会超过 3 万笔,用 small integer 即可,不必用integer。
• 文字数据字段若长度固定,如:身分证号码,就不要用varchar或nvarchar,应该用 char 或nchar。
• 文字数据字段若长度不固定,如:地址,则该用varchar或nvarchar。除了可节省存储空间外,存取硬盘时也会较有效率。
• 设计字段时,若其值可有可无,最好也给一个默认值,并设成「不允许 NULL」(一般字段默认为「允许 NULL」)。因为SQL Server在存放和查询有 NULL 的数据表时,会花费额外的运算动作 [2]。
• 若一个数据表的字段过多,应垂直切割成两个以上的数据表,并可用同名的Primary Key 一对多连结起来,如:Northwind 的 Orders、Order Details 数据表。以避免在存取数据时,以「集簇索引 (clustered index)」扫描时会加载过多的数据,或修改数据时造成互相锁定或锁定过久。
2、适当地建立索引
• 记得自行帮Foreign Key字段建立索引,即使是很少被JOIN的数据表亦然。
• 替常被查询或排序的字段建立索引,如:常被当作WHERE子句条件的字段。
• 用来建立索引的字段,长度不宜过长,不要用超过20个Byte的字段,如:地址。
• 不要替内容重复性高的字段建立索引,如:性别;反之,若重复性低的字段则适合建立索引,如:姓名。
• 不要替使用率低的字段建立索引,以免浪费硬盘空间。
• 不宜替过多字段建立索引,否则反而会影响到「INSERT、UPDATE、DELETE」的性能,尤其是以「OLTP (联机事务处理;在线交易)」为主的网站数据库。
• 若数据表存放的数据很少,就不必刻意建立索引。否则可能数据库沿着存放索引的「树状结构」(Balanced Tree) 去搜寻索引中的数据,反而比扫描整个数据表还慢。
• 若查询时符合条件的数据很多,则透过「非集簇索引(non-clustered index)」搜寻的性能,反而 可能不如整个数据表逐笔扫描。
• 建立「集簇索引」的字段选择至为重要,会影响到整个索引结构的性能。要用来建立「集簇索引」的字段,务必选择「整数」类型 (键值会较小)、唯一、不可为 NULL。
3、适当地使用索引
• 有些书籍会提到,使用「LIKE、%」做模糊查询时,即使您已替某个字段建立索引 (如下方代码的 CustomerID 字段),但以常量字符开头才会使用到索引,若以万用字符 (%) 开头则不会使用索引,如下所示:
USE Northwind; GO SELECT * FROM Orders WHERE CustomerID LIKE ‘D%’; –使用索引 SELECT * FROM Orders WHERE CustomerID LIKE ‘%D’; –不使用索引 |
在SQL Server 2005执行完成后按Ctrl + L,可检阅如下图的「执行计划」。
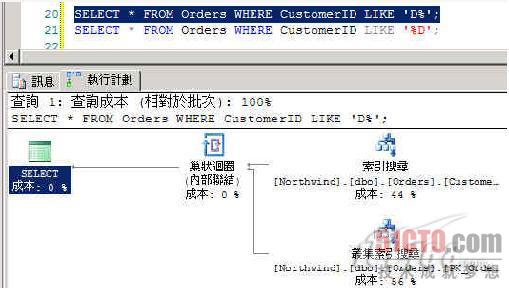
图 1
可看出「查询最佳化程序」有使用到索引做搜寻
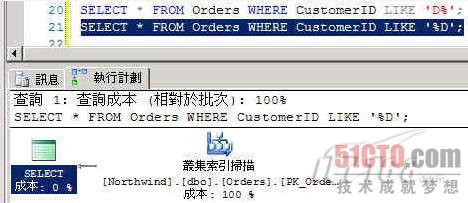
图 2
在此的「集簇索引」扫描,并未直接使用索引,性能上几乎只等于扫描整个数据表
但经反复测试,这种语法是否会使用到索引,抑或会逐笔扫描,并非绝对的。仍要看所下的查询关键词,以及字段内 所存储的数据内容而定。但对于存储数据笔数庞大的数据表,最好还是少用 LIKE 做模糊查询。
• 以下的运算符会造成「负向查询」,常会让「查询最佳化程序」无法有效地使用索引,最好能用其它运算符和语法改写 (经版工测试,并非有负向运算符,就绝对无法使用索引):
NOT 、 != 、 <> 、 !> 、 !< 、 NOT EXISTS 、 NOT IN 、 NOT LIKE |
• 避免让 WHERE 子句中的字段,去做字符串的串接或数字运算,否则可能导致「查询最佳化程序」无法直接使用索引,而改采「集簇索引扫描」(经版工测试并非绝对)。
• 数据表中的数据,会依照「集簇索引」字段的顺序存放,因此当您下 BETWEEN、GROUP BY、ORDER BY 时若有包含「集簇索引」字段,由于数据已在数据表中排序好,因此可提升查询速度。
• 若使用「复合索引」,要注意索引顺序上的第一个字段,才适合当作过滤条件。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
云端SQL Server高可用性最佳做法
与内部部署相比,在云端运行SQL Server可为数据库软件用户提供更多的灵活性和可扩展性,也可能更省钱。但云 […]
-
绘制数据关系图的利器:SQL Server 图像数据库工具
SQL Server 2017新增了图形数据库功能,你可以使用图结构来表示不同数据元素之间的关系。
-
如何在Azure部署时选择合适的SQL Server?
想要在Azure上运行SQL Server,企业一般会面临两种选择:在Azure虚拟机上安装SQL Server或使用Azure SQL Database。
-
Linux支持的引入 推动了SQL Server 2016集成服务的发展
随着SQL Server的不断发展,集成服务也在发生相应的变化。在最新的SSIS更新中,增加Linux支持和SQL Server 2016升级向导。