
如果你有两个数据来源,如平面文件或表数据,并且要将他们合并在一起,你将怎么做?如果他们有一个共同的属性,如客户ID,那么该解决方案应该是很明显:合并相关的属性,在这个例子中,只需合并客户ID就够了。如果没有任何共同之处该怎么办呢?唯一的要求就是,将数据源1中的记录和数据源2中的记录进行匹配 。并且,那个记录去和另一个记录匹配并没有关系,那么问题是,一个数据源中的每一个纪录如何获得从其他数据源记录的标记。
上述问题可以被描述为向一个数据库中加入了不同的或看似无关的数据。在先前的文章的文章中,涉及如何使用ROWNUM在无关的数据之间创造联系。该合并方法的本质是利用甲骨文提供虚拟数据列来建立联系。下面的查询可以用来作为CREATE TABLE AS SELECT声明的一部分或作为基于满足加入条件既定目标表的插入。
SELECT * FROM (SELECT , ROWNUM AS rownum_a FROM TABLE_A ) ALIAS_A, (SELECT , ROWNUM AS rownum_b FROM TABLE_B ) ALIAS_B WHERE ALIAS_A.rownum_a = ALIAS_B.rownum_b; |
假设要合并的记录的数目过大(如数以百万计),这种方法潜在的缺点是什么?那么,当一行作为一个记录时又如何了?我们没有真正的控制权决定的查询所返回结果行的顺序,直到我们执行查询之前,甲骨文是不知道记录的行号的。换言之, ROWNUM是在这样的事实上创建的。如果你要从两个地方选择数百万行,你将支付甲骨文公司为每个记录分配行号(只针对你的查询,而不是永远)的时间。
让我们监测将两个有100万行的表合并到一起的一个会话。在这第一个例子中,这个数据源已经记录可100万个记录。表A范围从1到1000000及表B 范围从1000001至2000000 (即在第一个表中再加入100万行) 。如果加入后能够完美的保持行的顺序,那么有序对将像下面表格这个样子:
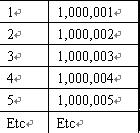
当我们查看数据时(通过Toad)发现Oracle数据库并不执行一个完美的排序,并且相差甚远。
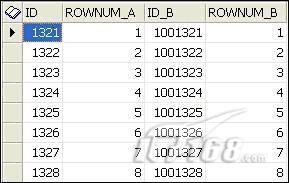
该ROWNUM_A和B值一个一个都匹配,因为这是我们匹配/合并的。注意:记录1321 (和1001321 )是如何同ROWNUM 1标记在一起的 。所以我们可以推断是,甲骨文以同样的方式填补表格之间的空白区块。这应该说服你一次甚至永远(如果你至今还不知知道), ROWNUM虚拟数据列已没有意义或与个表中记录的实际顺序无关。
创建表的声明追踪, 经过TKPROF 解析后,输出结果如下:
|
CREATE TABLE TABLE_ROWNUM AS |
我们知道一个事实,即每个表都有100万行。在分析了表后, NUM_ROWS值显示为1034591 。当与甲骨文本身将通过连续计数报告的值相比较时要小心依靠通过第三方工具检查出的值(包括从USER_TABLES选择NUM_ROWS )。为什么会有差异呢?是否是因为分析是基于样本或估算的数据,或根据检查到的每个记录?
现在,对于合并数据有一个可供选择的办法。那就是让我们使用一个真正的列替代虚拟数据列,一个自然的选择是创建(在某种意义上)基于序列替代关键字。这个办法是为每个表添加一个命名为SEQ的列,并且在基于序列号对他们进行更新,并且保证每次更新使用相同的起点和相同的增量。对一个表更新操作如下所示。
| SQL> create sequence tab_b; Sequence created. Elapsed: 00:00:00.05 SQL> update table_b set seq = tab_b.nextval; 1000000 rows updated. Elapsed: 00:05:00.05 |
有一件事应该可以立即脱颖而出:创造一个合并关键字所花费的时间刚刚超过五分钟,或是ROWNUM采取的方法所花费时间的13倍,这只是对两个表中的一个表所进行操作所花费的时间(第一张表格花费五分钟进行更新) 。增加或创建一个合并关键字是必要的,如有可能,最好在创建表的时候就创建。那么,比通过ROWNUM做同样的事情所多花费的关键点是什么?
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
翻译
相关推荐
-
Collaborate 18大会:了解甲骨文云数据库和应用的进展
在Collaborate 18大会即将举行时,我们会发现,甲骨文用户社区的技术变化会略高于平常水平。 由独立甲 […]
-
甲骨文自治数据库亮相 带来云计算新希望
早前甲骨文还不在云计算公司之列,而现在该公司正在迅速弥补其失去的时间。甲骨文的云计算核心是甲骨文自治数据库(O […]
-
2017年12月数据库流行度排行榜 定格岁末排名瞬间
数据库知识网站DB-engines最近更新的2017年12月份数据库流行度排名情况是否能提供更多的看点呢?TechTarget数据库网站将与您分享12月份的榜单排名情况,让我们拭目以待。
-
2017年11月数据库流行度排行榜 半数以上数据库积分减少
数据库知识网站DB-engines更新了2016年11月份的数据库流行度排行榜。TechTarget数据库网站将与您一同关注11月份的榜单排名情况。