
每当我们发现表的结构不正确的话,一般都会使用alter语句对表的结构进行修改,但是alter表结构,会引起一些开销,但这些开销,我们很可能就会忽视。但是这些开销在某些情况下,会给我们的数据库带来很大的影响,例如:对于数据的存储空间,有可能会引起数据库存储空间的急剧膨胀。这个有没有耸人听闻呢?下面就用例子来说明这一点。
基本的思路与要求:
1、 首先清楚数据行在sql 中是如何存储的。可以参见:
http://blog.csdn.net/HEROWANG/archive/2009/11/04/4769430.aspx
2、在验证的过程中会使用到两个命令:
DBCC IND、DBCC PAGE
一、问题:
Use test
go
if object_id(‘tb’) is not null
drop table tb
go
create table tb(id int identity(1,1), col char(985))
insert into [tb]
select ‘aaaa’ union all
select ‘bbbb’ union all
select ‘cccc’ union all
select ‘dddd’ union all
select ‘eeee’ union all
select ‘ffff’ union all
select ‘gggg’ union all
select ‘hhhh’ union all
select ‘iiii’ union all
select ‘jjjj’
exec sp_spaceused ‘tb’
|
name |
rows |
reserved |
data |
index_size |
unused |
|
tb |
10 |
24 KB |
16 KB |
8 KB |
0 KB |
所占用的数据页为2页,16K,按照数据行在页面中的存储方式可以计算出来:
存储一行数据需用的空间:(7+4+985+2)=998B,
1一个数据页可以存储的行数为:8096/998=8.1,所以需要两个页面来进行存储。
下面修改表的结构:
alter table tb
alter column col char(1000)
exec sp_spaceused ‘tb’
name | rows | Reserved | data | index_size | unused |
tb | 10 | 32 KB | 24 KB | 8 KB | 0 KB |
按照数据行在页面中的存储方式来计算:
修改后每一行的数据的空间应该为:(7+4+1000+2)=1013B
1一个数据页可以存储的行数为:8096/1013=7.99,所以似乎需要两个页面来进行存储,但是实际上修改后占用了3个页面。那么问题出在什么地方呢?原因在于当我们对表的结构进行修改的时候,对数据的存储产生了很大影响。
二、建立测试环境
Use test
go
if object_id(‘tb’) is not null
drop table tb
go
create table tb(id int identity(1,1), col char(985))
insert into [tb]
select ‘aaaa’ union all
select ‘bbbb’ union all
select ‘cccc’ union all
select ‘dddd’ union all
select ‘eeee’ union all
select ‘ffff’ union all
select ‘gggg’ union all
select ‘hhhh’ union all
select ‘iiii’ union all
select ‘jjjj’
三、DBCC IND、DBCC PAGE
1、DBCC IND
DBCC IND
(
[‘dbname’|dbid], — 数据库名或ID
tbname, — 表名
Printopt|noclustered index_id [, –输出选项
Partition_num] –-指定分区号,主要兼容2000
)
Printopt : –输出选项(常用的)
– noclustered index_id 所有IAM、数据及指定索引的分页信息
– -2 所有IAM页面
– -1 所有的数据、索引、IAM、行溢出及LOB页面
– 0 行内数据、行内数据的IAM页面
– 1 聚集索引及所有数据、IAM、LOB页面
例:DBCC IND(test,tb,0)

注:因为输出列数比较多,只截取了一部分图。在这里主要关注最后一列 pagetype
Pagetype为1,说明该页为数据页。
2、DBCC PAGE
DBCC TRACEON(3604)
– 必须先打开跟踪3604来让DBCC PAGE的结果输出给客户端。
DBCC PAGE(test,1,114,1)
–1为上图的pagefid,114为pagepid,
–1为输出方式,对每记录行分别输出缓冲及页面报头,行偏离表
结果:(只关注一些在这里要用到的数据)
PAGE: (1:114)–查看的是数据页
BUFFER: — 当前页面调入内存时,要为了便于管理内存中这个页面生成的一种结构
PAGE HEADER:–96个字节页头部结构
DATA: –数据部分
Slot 0, Offset 0x60, Length 996, DumpStyle BYTE
/**************
Offset 0x60:第一行的偏移量,为前面的96个头部结构,0x60=96
Length 996:数据的长度:996=7(存储每行数据需要的空间)+4(第一列的int长度)+985(第二例char的长度)
*************/
00000000: 1000e103 01000000 61616161 20202020
……省略
000003E0: 200200fc
0200:该表有两列
Slot 1, Offset 0x444, Length 996, DumpStyle BYTE
/**************
Offset 0x444:第二行的偏移量,0x444=1092=996(第一行的长度)+96(头部结构)
*************/
…… 省略
OFFSET TABLE:/*每一行的偏移量*/
Row – Offset
7 (0x7) – 7068 (0x1b9c)
6 (0x6) – 6072 (0x17b8)
5 (0x5) – 5076 (0x13d4)
4 (0x4) – 4080 (0xff0)
3 (0x3) – 3084 (0xc0c)
2 (0x2) – 2088 (0x828)
1 (0x1) – 1092 (0x444)
0 (0x0) – 96 (0x60)
四、查看修改表结构后的页面数据
alter table tb
alter column col char(1000)
DBCC IND(test,tb,0)

DBCC TRACEON(3604)
DBCC PAGE(test,1,114,1)
结果:(只关注这里要用到的数据)
DATA:
Slot 0, Offset 0x60, Length 9, DumpStyle BYTE
00000000: 04af0000 00010002 00 –第一行的数据
Slot 1, Offset 0x69, Length 1996, DumpStyle BYTE
00000000: 1000c907 02000000 62626262 20202020 †……..bbbb
……
000003E0: 20626262 62202020 20202020 20202020 † bbbb
……
000007C0: 20202020 20202020 200300f8
观察这里的数据,我们会发现这么两个问题:
1、第一行数据slot 0 去哪儿了?怎么只剩下9个字节?
2、第二行数据slot 1,长度 length 为什么是1996,而不是上面计算的1013呢?
仔细看下第二行的数据,就会发现bbbb出现了两次,所以1996是在原来的基础上,再加了1000,即当我们修改表的时候,并不是修改列的空间,而是在每一行后面增加新的一列。所以1996=7+4+985+1000。而倒数第三个字节也说明了这一点:0300 说明该表现在有三列,而不是原来的两列。
第一个问题暂时保留,接着往下看,就会发现答案
DBCC PAGE(test,1,175,1)(第二个数据页)
结果:
DATA:
Slot 0, Offset 0x1014, Length 1996, DumpStyle BYTE
1000c907 09000000 69696969 20202020 †……..iiii
……
20202020 20202020 200300f8
Slot 1, Offset 0x17e0, Length 1996, DumpStyle BYTE
1000c907 0a000000 6a6a6a6a 20202020 †……..jjjj
……
20202020 20202020 200300f8
Slot 2, Offset 0x60, Length 2010, DumpStyle BYTE
3200c907 01000000 61616161 20202020 †2…….aaaa
……
20202020 20202020 200300f8 0100da87 † …….
00047200 00000100 0000
Slot 3, Offset 0x83a, Length 2010, DumpStyle BYTE
3200c907 03000000 63636363 20202020 †2…….cccc
20202020 20202020 200300f8 0100da87
00047200 00000100 0200
OFFSET TABLE:(第二页的行偏移)
Row – Offset
3 (0x3) – 2106 (0x83a)
2 (0x2) – 96 (0x60)
1 (0x1) – 6112 (0x17e0)
0 (0x0) – 4116 (0x1014)
观察这里的数据:上面的第一个问题视乎找到了答案。
1、 因为第一页的数据需要分页,所以就把第一行的数据和第三行数据,放到了第二个页。
而第一页的其他两行数据因为第二页放不下,所以放在第三页中。
2、 第三行也就是slot2,存储的恰好就是从第一页分出来的aaaa这一行的数据,但是为什么它的偏移是96,也就是说在第二数据页的第一行存储的是aaaa,而不是原来的iiii。
原因:当我们修改表的结构,会把原来的数据向后移动,这样原来的空间就空出来。这个时候,把从第一页分离出来的数据,就写到第二页里面,这样,aaaa恰好写在第一页,所以他的偏移为96,而原来的iiii和jjjj反而不在原来的地方。
如下图所示:
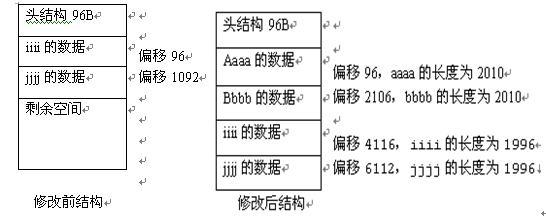
接着往下看:
DBCC PAGE(test,1,45,1)
DATA:
Slot 0, Offset 0x452, Length 2010, DumpStyle BYTE
00000000: 3200c907 05000000 65656565 20202020 …….eeee
……
000007C0: 20202020 20202020 200300f8 0100da87
000007D0: 00047200 00000100 0400
Slot 1, Offset 0x101e, Length 2010, DumpStyle BYTE
00000000: 3200c907 07000000 67676767 20202020…….gggg
……
000007C0: 20202020 20202020 200300f8 0100da87
000007D0: 00047200 00000100 0600
……
OFFSET TABLE:
Row – Offset (第二页的行偏移)
1 (0x1) – 4126 (0x101e)
0 (0x0) – 1106 (0x452)
最后的几个问题:
1、综合观察上面的数据,有些行的长度为1996,而有些行的长度为2010。而长度为2010的行,恰好都是从第一页分出来的数据。然后结合上面的二进制数据,似乎可以得到这个结果:
1)、没有分离的数据,那么在后面加上一个新列,长度为修改后的列的长度
1996=7+4+985+1000;
2)、而被分离的数据,除了加上新列,还有在后面加上一个长度为14字节的数据,至于这14个字节做什么,还尚不清楚。但是其中最后字节数据很有趣:
0000 aaaa
0200 cccc
0400 eeee
0600 ffff
恰好是该数据在原来表中行数,巧合还是有一定意义?
五、总结:
1、修改表的时候,并不是扩充原来列的存储空间,而是在表的后面增加一个新的列
2、增加了新列后,可能会引起数据的分页。如果原来的数据不分页的话,那么数据就整体向后移动。如果要分页的话,那么最后一页的数据,向后移动后,前面就留有空间,先向最后一页的空闲空间写数据,如果写不下,则分配新的数据页,来存储数据。
3、如果数据进行分页后,对于没有分离的数据,那么在后面增加一个新列;对于分离的数据,除了增加一个新列外,还额外增加14字节的数据
这样,我们基本上就能估算出,修改表,需要的存储空间上的开销了(只能是大概的,因为对于分离的数据,在原来的数据页上还会保留9个字节空间,对于分页后的数据后面还有14个字节的空间),修改表结构后,存储每行数据需要的空间为:7+4+1985+2=1998B
这样每页最多只能存储4行数据。
如果该表的数据量很大的话,这个开销就会很大,我们是不能忽视这个开销的。
六、解决方法:
上有政策,下有对策。本方法实际的实际可行性,没有验证。(没有生产环境,不好测试)。
1、 新建一张表,当然是修改结构后的表
2、 Insert into tb2 Select * from tb1
3、 重命名tb2为tb1
七、尚存的问题:
1、分页的行,在原来数据页中保留的九个字节的作用?
2、分页的数据,最后加的14个字节的作用
3、最后一页的行偏移是怎么偏移的。
4、在前面,我们已经看到,修改表的结构其实是在表的后面增加一个新的列,那么sql server如何知道从哪块开始读取该列的数据呢?
要来解答这三个问题,需要从上面的DBCC中取出如下的数据,然后进行分析,就可以知道第一个和第二个问题的答案了。
|
原来数据的九个字节 |
分页后数据的14个字节 |
|
04af0000 00010002 00 |
0100da87 00047200 00000100 0000 |
|
04af0000 00010003 00 |
0100da87 00047200 00000100 0200 |
|
042d0000 00010000 00 |
0100da87 00047200 00000100 0400 |
|
042d0000 00010001 00 |
0100da87 00047200 00000100 0600 |
1、分页的行,在原来数据页中保留的九个字节的作用?
数据分页以后,在原来的位置会有一个长度为9个字节的数据,这个数据的作用是:给出了数据转移到什么位置。第一个字节 04为状态位;下面四个字节af0000 00为页面id,转换为十进制为175,恰好就是aaaa数据转移后所在的页面号;下面的两个字节0100为文件号;最后的两个字节为数据转移后的所在数据页面的slot号。
2、分页的数据,最后加的14个字节的作用
分页后数据的14个字节:前面六个字节0100da870004 ,暂时只发现只要转移过,都是这个值,具体含义尚不清楚。后面的8个字节的左右是:给出了这个数据原来的位置。
第七个到第十个字节7200 0000(转换为十进制为144)为数据原来的数据页。下面的两个字节0100为文件号;最后的两个字节为数据转移前的所在数据页面的slot号。
3、最后一页的行偏移是怎么偏移的。
1)、当数据少于8个页面时使用混合类型的区
2)、SQLSERVER对页面原使用原则在磁盘空间不足时才考虑回收 ,当一个历史页面被使用后删除数据时是不会触动数据的,所以混合区给调用后直接根据页面上的freeData跳至指定区写入数据
3)、因为我们都是在堆表上进行的
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
OpenWorld18大会:Ellison宣布数据库的搜寻和破坏任务
在旧金山举行的甲骨文OpenWorld 2018大会中,甲骨文首席技术官(CTO)兼创始人Larry Elli […]
-
ObjectRocket着力发展Azure MongoDB服务
MongoDB吸引了微软公司的注意力,微软公司计划针对运行于该公司2017年发布的Azure Cosmos D […]
-
数据库和数据仓库的区别在哪儿?
目前,大部分数据仓库还是用数据库进行管理。数据库是整个数据仓库环境的核心,是数据存放的地方和提供对数据检索的支持。
-
如何使用服务来平衡Oracle RAC 数据库工作负载
为不同的应用程序配置不同的服务,DBA可以更有效地平衡集群工作负载,在Oracle RAC数据库环境下实现更好的应用程序性能。