
HBase
HBase是一个分布式的、面向列的开源数据库,该技术来源于Chang et al所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Googl文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.另一个不同的是HBase基于列的而不是基于行的模式。HBase使用和Bigtable非常相同的数据模型。用户存储数据行在一个表里。一个数据行拥有一个可选择的键和任意数量的列。表是疏松的存储的,因此用户可以给行定义各种不同的列。HBase主要用于需要随机访问,实时读写你的大数据(Big Data)。
Berkeley DB Java Edition
Berkeley DB Java Edition (JE)是一个完全用JAVA写的,它适合于管理海量的,简单的数据。 能够高效率的处理1到1百万条记录,制约JE数据库的往往是硬件系统,而不是JE本身。 多线程支持,JE使用超时的方式来处理线程间的死琐问题。 Database都采用简单的key/value对应的形式。 事务支持。 允许创建二级库。这样我们就可以方便的使用一级key,二级key来访问我们的数据。 支持RAM缓冲,这样就能减少频繁的IO操作。 支持日志。 数据备份和恢复。 游标支持。
Neo4j
Neo4j是一个嵌入式,基于磁盘的,支持完整事务的Java持久化引擎,它在图像中而不是表中存储数据。Neo4j提供了大规模可扩展性,在一台机器上可以处理数十亿节点/关系/属性的图像,可以扩展到多台机器并行运行。相对于关系数据库来说,图形数据库善于处理大量复杂、互连接、低结构化的数据,这些数据变化迅速,需要频繁的查询——在关系数据库中,这些查询会导致大量的表连接,因此会产生性能上的问题。Neo4j重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。通过围绕图形进行数据建模,Neo4j会以相同的速度遍历节点与边,其遍历速度与构成图形的数据量没有任何关系。此外,Neo4j还提供了非常快的图形算法、推荐系统和OLAP风格的分析,而这一切在目前的RDBMS系统中都是无法实现的。
Neo是一个网络——面向网络的数据库——也就是说,它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络上而不是表中。网络(从数学角度叫做图)是一个灵活的数据结构,可以应用更加敏捷和快速的开发模式。
你可以把Neo看作是一个高性能的图引擎,该引擎具有成熟和健壮的数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
由于使用了“面向网络的数据库”,人们对Neo充满了好奇。在该模型中,以“节点空间”来表达领域数据——相对于传统的模型表、行和列来说,节点空间是很多节点、关系和属性(键值对)构成的网络。关系是第一级对象,可以由属性来注解,而属性则表明了节点交互的上下文。网络模型完美的匹配了本质上就是继承关系的问题域,例如语义Web应用。Neo的创建者发现继承和结构化数据并不适合传统的关系数据库模型:
- 对象关系的不匹配使得把面向对象的“圆的对象”挤到面向关系的“方的表”中是那么的困难和费劲,而这一切是可以避免的。
- 关系模型静态、刚性、不灵活的本质使得改变schemas以满足不断变化的业务需求是非常困难的。由于同样的原因,当开发小组想应用敏捷软件开发时,数据库经常拖后腿。
- 关系模型很不适合表达半结构化的数据——而业界的分析家和研究者都认为半结构化数据是信息管理中的下一个重头戏。
- 网络是一种非常高效的数据存储结构。人脑是一个巨大的网络,万维网也同样构造成网状,这些都不是巧合。关系模型可以表达面向网络的数据,但是在遍历网络并抽取信息的能力上关系模型是非常弱的。
虽然Neo是一个比较新的开源项目,但它已经在具有1亿多个节点、关系和属性的产品中得到了应用,并且能满足企业的健壮性和性能的需求:
完全支持JTA和JTS、2PC分布式ACID事务、可配置的隔离级别和大规模、可测试的事务恢复。这些不仅仅是口头上的承诺:Neo已经应用在高请求的24/7环境下超过3年了。它是成熟、健壮的,完全达到了部署的门槛。
NeoDatis ODB
NeoDatis ODB是一个面向对象数据库,一个真正透明的对象持久层。利用一行简单的代码就能够持久化native object。ODB非常简单、非常快并自带强大查询语言。ODB既可以做为一个内嵌数据库引擎使用,也可以以C/S模式运行。
Apache Cassandra
Apache Cassandra是一套开源分布式 Key-Value 存储系统。它最初由 Facebook 开发,用于储存特别大的数据。 Cassandra 不是一个数据库,它是一个混合型的非关系的数据库,类似于 Google 的 BigTable。本文主要从以下五个方面来介绍 Cassandra:Cassandra 的数据模型、安装和配制 Cassandra、常用编程语言使用 Cassandra 来存储数据、Cassandra 集群搭建。Cassandra是一个混合型的非关系的数据库,类似于Google的BigTable。其主要功能比Dynomite(分布式的Key-Value存储系统)更丰富,但支持度却不如文档存储MongoDB(介于关系数据库和非关系数据库之间的开源产品,是非关系数据库当中功能最丰富,最像关系数据库的。支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。)Cassandra最初由Facebook开发,后转变成了开源项目。它是一个网络社交云计算方面理想的数据库。以Amazon专有的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型。P2P去中心化的存储。很多方面都可以称之为Dynamo 2.0。
Cassandra 的数据模型是基于列族(Column Family)的四维或五维模型。它借鉴了 Amazon 的 Dynamo 和 Google’s BigTable 的数据结构和功能特点,采用 Memtable 和 SSTable 的方式进行存储。在 Cassandra 写入数据之前,需要先记录日志 ( CommitLog ),然后数据开始写入到 Column Family 对应的 Memtable 中,Memtable 是一种按照 key 排序数据的内存结构,在满足一定条件时,再把 Memtable 的数据批量的刷新到磁盘上,存储为 SSTable 。
Voldemort
Voldemort是一个分布式键-值(Key-value)存储系统,是Amazon’s Dynamo的一个开源克隆。
- 支持自动复制数据到多个服务器上。
- 支持数据自动分割所以每个服务器只包含总数据的一个子集。
- 提供服务器故障透明处理功能。
- 支持可拨插的序化支持,以实现复杂的键-值存储,它能够很好的5.集成常用的序化框架如:Protocol Buffers、Thrift、Avro和Java Serialization。
- 数据项都被标识版本能够在发生故障时尽量保持数据的完整性而不会影响系统的可用性。
- 每个节点相互独立,互不影响。
- 支持可插拔的数据放置策略。
Perst
Perst 是一个面向对象的开源嵌入式数据库软件, 能够有效的处理移动设备上的大量数据。Perst 是McObject 公司发布的一款非常袖珍的开源嵌入式数据库, 是一个简单, 快速, 便捷, 面向对象, 适合java 与.NET 的数据库。Perst 不需要专门的编译器与预处理器, 支持ACID 事务。对于在资源受限的移动设备( 如手机, PDA 等)上存储大量数据和对数据进行频繁的IO 操作往往要消耗很多的设备资源。由于移动设备内存小, 性能较差, 如果采用关系数据库( 如SQLServer2000, Oracle) 管理数据, 仅靠其有限的内存资源是不能运行这些数据库管理系统的, 这样就有必要采用一些特殊的数据库系统。Perst 数据库正是为这类设备研究开发的, 它们的作用是在资源受限的设备上完成大量数据的访问操作。其实这些设备系统资源主要消耗在从磁盘上读取数据的IO 操作。如何提供一种有效的文件存储策略来降低对磁盘的IO 操作是嵌入式数据库软件设计的主要任务。
像其他嵌入式数据库一样,Perst没有管理上的代价,但不同的是Perst直接将对象以Java或者C#对象的形式进行存储。因此不需要在对象的内部表现形式和Java/C#表现形式之间转换。这个数据库引擎非常精悍,只有约5000行代码,McObject对此感到骄傲。根据访问模式不同,运行时需要30K到300K的内存。
Terrastore
Terrastore是一个基于Terracotta(一个业界公认的、快速的分布式集群组件)实现的高性能分布式文档数据库。可以动态从运行中的集群添加/删除节点,而且不需要停机和修改任何配置。支持通过http协议访问Terrastore。Terrastore提供了一个基于集合的键/值接口来管理JSON文档并且不需要预先定义JSON文档的架构。易于操作,安装一个完整能够运行的集群只需几行命令。
HyperGraphDB
HyperGraphDB是一个通用,可扩展,可移植的,分布式,可嵌入的开源数据存储机制。专为人工智能和语义Web项目而设计。它也可以用来作为一个适用于各种规模项目的嵌入式面向对象数据库。HyperGraphDB是一个基于Java的产品,构建在Berkeley DB存储类库之上。它的主要特性包括:
- 支持广义图存储。开放,可扩展的类型系统。
- 基本查询系统和图形的遍历算法。
- 支持Java对象直接存储。
- 线程安全的事务处理。
- 提供P2P框架实现数据分发。
OrientDB
OrientDB是兼具文挡数据库的灵活性和图形数据库管理链接能力的可深层次扩展的文档-图形数据库管理系统。可选无模式、全模式或混合模式下。支持许多高级特性,诸如ACID事务、快速索引,原生和SQL查询功能。可以JSON格式导入、导出文档。若不执行昂贵的JOIN操作的话,如同关系数据库可在几毫秒内可检索数以百记的链接文档图。
HandlerSocket client for java
HandlerSocket是一个MySql插件,可以将mysql作为NoSQL来使用。通过这个插件,你可以直接跟MySql后端的存储引擎做key-value式的交互,省去了MySql上层的SQL解释、打开关闭表、创建查询计划等CPU消耗型的开销。hs4j是HandlerSocket的一个java客户端。HS4J的使用很简单,所有的操作都通过HSClient这个接口进行。HS4J同样支持连接池,可以在构建客户端的时候传入连接池大小。
相关文章:http://rdc.taobao.com/team/jm/archives/545
Tair: 淘宝的key/value解决方案
Tair是一个分布式的key/value结构数据的解决方案,系统默认支持基于内存和文件的存储引擎,对应于通常我们所说的缓存和持久化存储。
Tair具有良好的架构,使得其在可扩展性、数据安全性方面都有较好的表现:
- 基于对照表的灵活、良好的可扩展性
- 轻量级的configserver
- 抽象的存储引擎层,支持添加新的存储引擎
- 自动的复制和迁移,对用户透明
- 多机架和多数据中心的支持
- 插件容器
Tair除了基本的key/value操作外,还提供了一些实用的功能,使得其适用的场景更多:
- 数据的version支持
- 原子计数器支持
- item支持
相关文章:http://rdc.taobao.com/blog/cs/?p=302#more-302
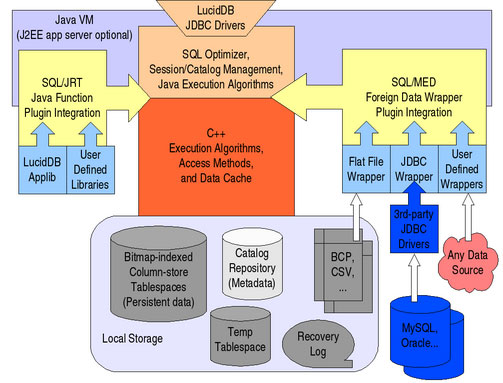
LucidDB
LucidDB是唯一一款专注于数据仓库和商务智能的开源RDBMS,它使用了列存储架构,支持位图索引,哈希连接/聚合和页面级多版本,大部分数据库最初都注重事务处理能力,而分析功能都是后来才加上去的。相反,LucidDB中的所有组件从一开始就是为满足灵活的需求,高性能数据集成和大规模数据查询而设计的,此外,其架构设计彻底从用户出发,操作简单,完全无需DBA。
LucidDB对硬件要求也极低,即使不搭建集群环境,在单一的Linux或Windows服务器上也能获得极好的性能。最新版本还加入了对Mac OS X和Windows 64位的支持,官方网站上的文档和教程也非常丰富,非常值得你体验一下。
Couchdb4j
Couchdb4j是一个Java开源类库用于与基于JSON的CouchDB数据库交互。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
MongoDB收购Realm数据库以增强移动力量
日前MongoDB公司宣布收购开源数据库供应商Realm公司,以帮助其在日益移动化计算领域提升竞争能力。 Re […]
-
低成本和云选项推动开源RDBMS的部署
随着企业产生越来越多的数据,数据专业人员面临困境:在此过程中数据库账单必须变得更多吗?对此,越来越多注重成本的 […]
-
TT百科:SAP SQL Anywhere
SAP SQL Anywhere可以从物联网设备捕获数十亿比特的数据,如传感器和其他互联网产品,并把它与企业业务数据相结合。
-
NoSQL性能管理仍不完备 你该如何应对?
NoSQL技术现在仍然处于相对初级的阶段,众多NoSQL软件类型和产品服务令人眼花缭乱,选择合适的性能管理方案也成为一件颇具挑战性的事。