
尽管Hadoop适合大多数批处理工作负载,而且在大数据时代成为企业的首选技术,但由于以下几个限制,它对一些工作负载并不是最优选择:
- 缺少对迭代的支持
- 需要将中间数据存在硬盘上以保持一致性,因此会有比较高的延迟
当然,整个Hadoop生态系统是在不断演进的,包括Map/Reduce已经证明是处理大规模海量数据的理想方式。而HDFS、HBase等在过去几年中也有了长足的进步。
在本文中,我们将深入了解一下过去一年中“红透半边天”的技术Spark,它与Hadoop架构类似,但是在许多方面都弥补了Hadoop的不足,比如在进行批处理时更加高效,并有更低的延迟。在大数据时代,Spark给我们带了新的选择,它的前途不可限量。
在Spark集群中,有两个重要的元素,即driver和worker。driver 程序是应用逻辑执行的起点,而多个worker用来对数据进行并行处理。尽管不是强制的,但数据通常是与worker搭配,并在集群内的同一套机器中进行分区。在执行阶段,driver程序会将code/closure传递给worker机器,同时相应分区的数据将进行处理。数据会经历转换的各个阶段,同时尽可能地保持在同一分区之内。执行结束之后,worker会将结果返回到driver程序。
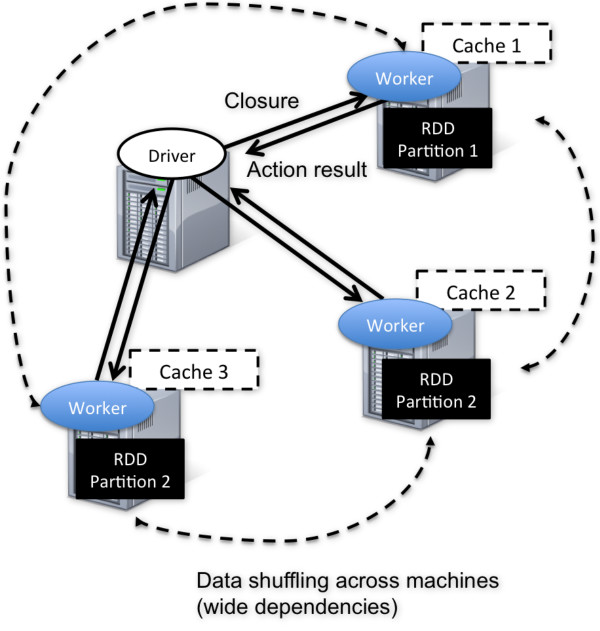
在集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(Resilient Distributed Dataset ,RDD),它是逻辑集中的实体,但在集群中的多台机器上进行了分区。通过对多台机器上不同RDD联合分区的控制,就能够减少机器之间数据混合(data shuffling)。Spark提供了一个“partition-by”运算符,能够通过集群中多台机器之间对原始RDD进行数据再分配来创建一个新的RDD。
RDD可以随意在RAM中进行缓存,因此它提供了更快速的数据访问。目前缓存的粒度在处在RDD级别,因此只能是全部RDD被缓存。在集群中有足够的内存时,Spark会根据LRU驱逐算法将RDD进行缓存。
RDD提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,而应用逻辑可以表达为一系列转换处理。
通常应用逻辑是以一系列TRANSFORMATION和ACTION来表达的。前者在RDD之间指定处理的相互依赖关系DAG,后者指定输出的形式。调度程序通过拓扑排序来决定DAG执行的顺序,追踪最源头的节点或者代表缓存RDD的节点。
Spark中的依赖性主要体现为两种形式,宽与窄(Narrow dependency,Wide dependency)。Narrow dependency是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。Wide dependency是指子RDD的分区依赖于父RDD的多个分区或所有分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区。注意Narrow dependency 的RDD可以通过相同的键进行联合分区,整个操作都可以在一台机器上进行,不会造成网络之间的数据混合。另一方面,Wide dependency的RDD就会涉及到数据混合。调度程序会检查依赖性的类型,将Narrow dependency 的RDD划到一组处理当中,即stage。Wide dependency在一个执行中会跨越连续的stage,同时需要显式指定多个子RDD的分区。
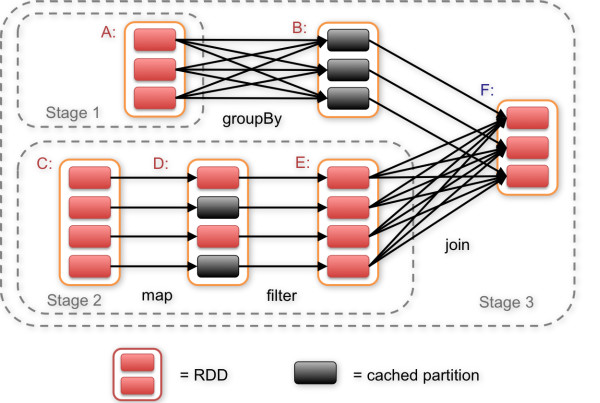
典型的执行顺序如下:
- RDD直接从外部数据源创建(HDFS、本地文件等)
- RDD经历一系列的TRANSFORMATION( map、flatMap、filter、 groupBy、join),每一次都会产生不同的RDD,供给下一个TRANSFORMATION使用
- 最后一步就是ACTION(count、collect、save、take),将最后一个RDD进行转换,输出到外部数据源。
上述一系列处理称为一个lineage,即DAG拓扑排序的结果。在lineage中生成的每个RDD都是不可变的。事实上,除非被缓存,每个RDD在进入下一个TRANSFORMATION前都只使用一次。
在一个典型的分布式系统当中,故障恢复是由主动监控系统以及不同机器之间的数据复制来实现的。当一台机器出现故障,其他的机器上总是会有一套数据副本来进行故障恢复。
而在Spark当中则采取了不同的方法。首先作为一个大型的集群,Spark并不应该是一个大规模数据集群。Spark针对工作负载会做出两种假设:
- 处理时间是有限的
- 保持数据持久性是外部数据源的职责,主要是让处理过程中的数据保持稳定
Spark在执行期间发生数据丢失时会选择折中方案,它会重新执行之前的步骤来恢复丢失的数据。但这并不是说丢弃所有之前已经完成的工作,而重新开始再来一遍。我们只需要再执行一遍父RDD的相对应分区。
需要知道,丢失分区的再执行其实与DAG的延迟计算一样的,它开始于DAG的叶节点,追溯父RDD需要的依赖性,然后逐渐追踪到源节点。丢失节点的重新计算其实与它非常类似,但它把分区作为额外的信息,以便决定需要哪些父RDD。
然而,跨Wide dependency的再执行能够涉及到多个父RDD从而引发全部的再执行。为了规避这一点,Spark会保持Map阶段中间数据输出的持久,以免它们混合到不同机器上执行reduce阶段。在机器发生故障的情况下,再执行只需要回溯mapper持续输出的相应分区,来获取中间数据。Spark还提供了检查点的API,明确持久中间RDD,这样再执行就不必追溯到最开始的阶段。未来,通过在恢复的延迟以及根据统计结果的check-pointing总开销之间进行权衡,Spark会自动化地执行check-pointing。
Spark为构建低延迟,大规模并行处理的大数据分析应用提供了强大的处理框架。它支持围绕RDD抽象的API,同时包括一套TRANSFORMATION和ACTION操作,以及针对大量流行编程语言的支持,比如Scala、Java和Python。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Cloudera-Hortonworks合并或将减少Hadoop用户的选择
近日大数据领域两家顶级供应商达成交易协议,这可能会影响Hadoop和其他开源数据处理框架,并使大数据用户的技术 […]
-
Azure数据湖分析从U-SQL中获得提升
大数据的发展已经让许多精通SQL的数据专业人员不知所措。微软的U-SQL编程语言试图让这些人回归数据查询游戏。
-
进入机器学习时代,数据库何去何从?
Vertica之前就已经能够对Hadoop数据进行访问,但Vertica8.0分析引擎则能够与Hadoop数据适当协作,如此一来就能减少数据迁移。
-
NoSQL——未来数据库家族的一员
NoSQL是对数据库由内而外的全方位改造,从而创造出一个高容量、高速度和高可变性的架构。然而,NoSQL供应商在可变性部分却正在遭遇失败。