
Pinterest是一家数据驱动的公司,我们持续的使用数据来做发布决策,所以开发有效的系统来快速的分析信息相当的重要。
我们最终选用了Redshift,它是基于亚马逊网络服务的数据仓库服务,它增强了我们的交互分析能力,每天尽可能快的导入数以亿计的记录,来确保核心数据源的可用性。Redshift是一个伟大的解决方案,它可以在几秒钟内回答问题来保证交互数据分析和快速的原型(然而Hadoop和Hive用来处理每天兆兆字节量级的数据,只能在几钟或者几个小时内给出答案)。
来看看我们在使用Redshift中的一起体验吧:包括了挑战和收获,这只是系统的数亿分之一的缩影。
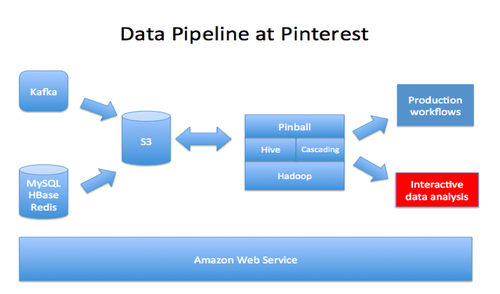
Redshift启动方便并且相当可靠,然而面对千万亿字节量级的大量数据和快速扩张的组织规模,在生产环境中使用Redshift,我们将会面对一些有趣的挑战。
挑战1: 创建100万亿字节量级的ETL完成从Hive到Redshift的转化
在Hive中有万亿字节量级的数据,它需要我们花一些时间来思考一个最佳的实践,如何把100万亿字节的核心数据导入到Redshift中。在Hive中有各种格式的数据,包括了原始的json,Thrift, RCFile,这些都需要转化成带有一个平面模式的文本文件。我们用Python撰写了模式映射的脚本,通过这些脚本生成Hive查询来处理重量级的ETL。
在Hive中,大部分的表都是时间序列数据且按日期分片。为了保证最佳结果,我们使用了日期作为排序键,每天在各张表后追加数据,从而避免高成本的VACUUM操作。另一种方法是每天使用一张表,通过视图把它们关联,但是我们发现Redshift没有很好的视图查询优化的机制(例如,它不能下压LIMIT)。
加载一张大的快照表同样是一件具有挑战的事情。我们最大的表db_pins它包括了200亿个Pins,在规模上远不止10TB的数据。在快照表中加载它会导致开销巨大的分片和排序,因此我们在Hive中做了大量的分片,同时逐块儿的加载到Redshift中。
由于Redshift只有有限的存储空间,我们采用表保留的方式去处理大数据的时间序列的表格,通过周期性的运行插入查询到Redshift中去将有限的数据拷贝到新的表格中,这样做会比删除行然后做耗费极高的清空,或者舍弃整个表再重新导入的方法要快得多。
也许最大的挑战是来自于S3最终的一致性。我们发现在Redshift中有时候会有严重的丢数据现象,然后追查下来是S3的问题。我们通过绑定一些小的文件的方法来减少在S3上的文件数量,这样来减少数据丢失。我们同时在ETL的每一步中添加审计,这样数据丢失率现在通常已经在可以接受的0.0001%以下。
挑战2:通过Redshift之外的Hives得到100x的速度提升
Redshift生来具备高性能,这使得在原型中对于一些查询不需要什么额外的努力,我们可通过Hive得到50-100x的提速,然而一旦进入生产环境,它并不总能像测试时那样与预期的性能相符。
在早期的测试中我们发现一些长达数小时的查询,调试性能问题是相当棘手的,这需要收集查询计划、查询执行统计等,但是最终它没有明显的性能问题。
由此得到的教训是需要把数据准备好,无论何时更新系统的统计信息是必须的,因为它会极大的影响优化的的工作。为每张表选择一个好的排序键和分区键,排序键会容易一些,但是糟糕的分区键将会歪曲和影响系统的性能。
下面是Hive 和Redshift聚簇的基准测试结果,测试基于db_pins(200亿行,每行有50个列的,总大小是10TB)和一些其它的核心表。要记得这些比较不包括聚簇大小,资源争用和其它可能的优化机制,因此比较一点也不科学。
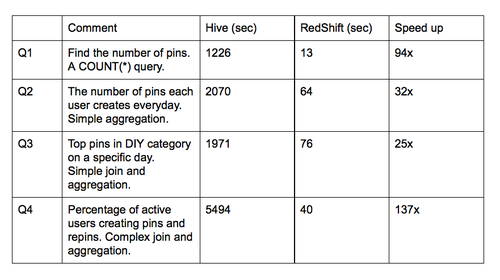
我们也发现了一些常识性的错误,总结了我们的最佳实践,创建了工具实时的监控速度慢的查询。耗时超过20分钟的被视为有嫌疑,工程师们就会收到提醒,来回顾我们遵守的最佳实践。

或许最常见的错误是趋向于把“Select *” 这样的内容放在select子句中,这有悖于列存储,因为它需要扫描全部非必需的列。
挑战3: 管理不断增长的查询/用户的争用。
因为性能良好,在我们配置好后,Redshift被广泛的应用到Pinterest中。我们是一个高速发展的机构,越来越多的人们对并行使用Redshift感兴趣,由于大量的查询争用资源,查询的速度明显的下降。一个代价较大的查询会占用大量的资源且明显的影响其它并行的查询,因此我们需要制定规则来使得争用最小化。
我们避免在峰值时段(上午9点到下午5点)使用重量级的ETL查询。ETL查询和COPY一样会占用大量的输入输出和网络带宽,为了保证用户的交互查询要避免在这些时段使用ETL查询。我们优化了ETL的管道使它在峰值时间之前完成,或者暂停管道,在峰值后再恢复。甚至于,在峰值时段暂停用户交互查询。可能包含错误的长查询将会被立即停止,而不是让它浪费资源。
目前状况
我们建了16个hs1.8xlarge性能的节点。通常在Pinterest上会有100个用户同时使用Redshift,每天我们运行300到500个交互式的查询。因为很多查询都能在几秒钟内完成,总体的性能超过了我们的预期。以下是上周交互式查询的持续百分比。我们可以看到75%的查询是可以在35秒内完成的。

因为我们成功的使用了Redshift,我们将继续将其集成到我们下一代的工具中。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
翻译
相关推荐
-
DBA不可不知的Amazon RedShift 性能监控工具
RedShift平台负担了大量的集群和数据库管理工作,但也并非面面俱到。有些AWS工具便填补了监控方面的空白。
-
第三方工具将弥补Amazon Redshift不足
虽然Amazon的Redshift数据仓库可以让SQL查询快速得到结果,但是一个第三方工具生态系统的易用性是非常关键的。
-
四问Amazon:如何选择云数据仓库服务
尽管Amazon Redshift和RDS都是面向分析的云服务,但它们的应用场景存在一定的差异。在采用这两项服务之前,你首先需要弄清楚几个问题。
-
RedShift将改变云数据仓库游戏规则
在过去,Teradata、Oracle等IT巨头基本上形成了对数据仓库市场的垄断。而随着云解决方案的出现,使得构建部署数据仓库的成本得到了极大程度的降低。