
Hadoop很火,但究竟什么是Hadoop?实际上,它并不是一个具体的软件。Hadoop是Apache软件基金会的一个项目,它包含了多个核心工具,用来处理海量数据以及大型计算集群。围绕Hadoop,有一个庞大的生态系统,而且市面上也有很多打包好的商业解决方案,我们通常将其称为Hadoop发行版(Hadoop Distribution),比如Cloudera、Hortonworks、IBM以及MapR等。每一个发行版都提供了多种工具的组合,与开源版本相比,商业发行版更适合企业级的大数据应用。
我们要明确一个概念,就是没有一个工具或一套工具可以称为“Hadoop”,所以当厂商向你推销Hadoop的时候,你要对此提起注意。厂商可能会提供一个或多个Hadoop工具的集成,有时甚至一个都没有,所以许多用户会对选择Hadoop感到疑惑。本文要介绍的SAP就是其中之一,接下来我们就将深入地介绍一下SAP的软件是如何与Hadoop结合的。
首先,我们来给Hadoop下一个定义。正如上文所提到的,Hadoop包含了一系列的核心工具,即:
- Hadoop分布式文件系统(HDFS),这是一个分布式的文件系统,可以运行在大型的集群当中,用来存储海量数据。其他的Hadoop工具都需要从HDFS中调取数据来进行处理。因此HDFS是Hadoop最核心的组件。
- YARN(Yet Another Resource Negotiator)是Hadoop的核心集群资源管理框架。它是Hadoop2.0中最重要的组件之一,大部分(当然不是全部)的Hadoop生态系统工具都运行在YARN集群上。
- MapReduce是对海量数据集进行并行处理的系统,它是在Google一篇论文基础上衍生出来的。虽然它是Hadoop最原始的组件,但有趣的是,许多商业版本提供商并没有直接使用MapReduce。
上面提到的只是Hadoop中最核心的组件,Hadoop生态系统中还包括很多实用工具,有些工具也是Apache软件基金会的项目,也有一些是其他开源项目。下面这些工具都是托管在Apache社区的:
- Hive——我们可以把它视为Hadoop的数据仓库工具,Hive事实上是一个分布式数据库,它拥有数据定义和查询语言HQL,它与标准的SQL十分类似。Hive表可以完全由Hive来管理,或者它们也可以在HDFS和HBase等数据源上定义为“外部”表。因此,Hive往往是Hadoop生态系统的数据存储出入口。
- Pig——它是一个编程语言和执行程序的平台,用来创建数据分析项目。
- HBase——这是一个大规模并行的数据库,它也是根据Google BigTable论文衍生而来。
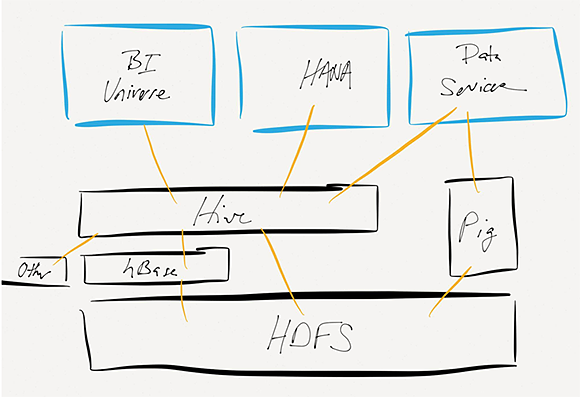
该图展示了SAP软件产品打通了哪些Hadoop工具,它只显示了数据访问的路径,并没有深入每一个工具的技术架构
- 其他的项目包括Spark(内存集群计算和流数据框架),Shark(Hive on Spark),Mahout(分析算法库),ZooKeeper(集中式信息维护服务),Cassandra(与HBase类似的数据库产品)。
那么,SAP的产品如何与这些Hadoop工具结合?产品的不同,其结合方式也会有所不同。目前为止,SAP在HANA、Sybase IQ、SAP Data Services以及BusinessObjects商业智能工具中都集成了Hadoop功能,但它们采取的方式有所区别。
SAP HANA和Sybase IQ都支持远程Apache Hive系统的转移查询,这使得用户在处理Hive数据库表的时候就像是在本地一样。在Sybase IQ中,这一功能称为“远程数据库”,在HANA中则是通过“智能数据访问(Smart DataAccess)”机制来实现的。Sybase IQ还支持MapReduce API来处理非结构化数据,除此之外,Sybase的数据库与Hadoop之间是无法打通的。
SAP BusinessObjects BI可以通过Universe的概念来支持Apache Hive模式的访问,它就像是连接其他数据库一样。这里需要注意的是,这种连接理论上是可以通过Hive的外部表概念访问多种不同的存储系统的,其中包括HBase,Cassandra以及MongoDB等。
上面所提到的SAP与Hadoop的结合只是针对Hive的,而通过HQL与Hive集成是最常见的,也是大多数厂商集成Hadoop的方式。但这与厂商所描绘的Hadoop系统深度集成是有所不同的。
SAP数据服务所做的比Hive集成更多。除了将数据从Hive当中导入导出之外,数据服务还可以直接创建并读取HDFS文件,同时做一些转换来使用Pig脚本实现一些操作。也就是说,数据可以直接在Hadoop集群当中进行联合与过滤,而无需再转移到特定的服务器上进行处理。SAP数据服务还可以将文本数据处理直接放到Hadoop集群上作为MapReduce任务来进行操作。所以SAP在Hadoop工具的深度集成方面,有着独特的优势。
最后提醒一下:Hadoop生态系统的发展是非常快的,而企业软件的发展却是比较滞后。根据SAP产品的生命周期介绍,目前只支持相对旧版本的Hive、Pig以及HDFS,一些新的功能改进,高可用性以及集群功能是不支持的。企业在进行选型的时候,需要仔细阅读厂商的支持文档,看看商业软件是否支持你想要的Hadoop工具。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
翻译
相关推荐
-
Cloudera-Hortonworks合并或将减少Hadoop用户的选择
近日大数据领域两家顶级供应商达成交易协议,这可能会影响Hadoop和其他开源数据处理框架,并使大数据用户的技术 […]
-
SAP为中小型企业ERP产品提供了更多资源
SAP Business ByDesign(简称BBD)是全功能的ERP产品,提供公有云解决方案,定位用于员工规模在350到1500人的公司。BBD和B1都是为了希望运行双层ERP的组织而设计的。
-
在SAP 创新中心展出的下一代技术
SAP创新中心展示了一些下一代技术,其中包括使用来自European Space Agency(欧洲空间局,ESA)的数据和机器学习来预测自然灾害的基于SAP HANA的应用程序。
-
SAP GRC对公司来讲意味着什么?
SAP GRC流程控制给公司提供公司级业务流程的全局视图。它提供了充分的灵活性可以设置自动或手动控制业务流程,所有流程可以被监视、测试和评估。