
应用篇
Hadoop平台释放了前所未有的计算能力,同时大大降低了计算成本。底层核心基础架构生产力的发展,必然带来的是大数据应用层的迅速建立。
对于Hadoop上的应用大致可以分为这两类:
IT优化
将已经实现的应用和业务搬迁到Hadoop平台,以获得更多的数据、更好的性能或更低的成本。通过提高产出比、降低生产和维护成本等方式为企业带来好处。
这几年Hadoop在数个此类应用场景中已经被证明是非常适合的解决方案,包括:
历史日志数据在线查询:传统的解决方案将数据存放在昂贵的关系型数据库中,不仅成本高、效率低,而且无法满足在线服务时高并发的访问量。以HBase为底层存储和查询引擎的架构非常适合有固定场景(非ad hoc)的查询需求,如航班查询、个人交易记录查询等等。现在已经成为在线查询应用的标准方案,中国移动在企业技术指导意见中明确指明使用HBase技术来实现所有分公司的清账单查询业务。
ETL任务:不少厂商已经提供了非常优秀的ETL产品和解决方案,并在市场中得到了广泛的应用。然而在大数据的场景中,传统ETL遇到了性能和QoS保证上的严重挑战。多数ETL任务是轻计算重IO类型的,而传统的IT硬件方案,如承载数据库的小型计算机,都是为计算类任务设计的,即使使用了最新的网络技术,IO也顶多到达几十GB。
采用分布式架构的Hadoop提供了完美的解决方案,不仅使用share-nothing的scale-out架构提供了能线性扩展的无限IO,保证了ETL任务的效率,同时框架已经提供负载均衡、自动FailOver等特性保证了任务执行的可靠性和可用性。
数据仓库offload:传统数据仓库中有很多离线的批量数据处理业务,如日报表、月报表等,占用了大量的硬件资源。而这些任务通常又是Hadoop所善长的
经常被问到的一个问题就是,Hadoop是否可以代替数据仓库,或者说企业是否可以使用免费的Hadoop来避免采购昂贵的数据仓库产品。数据库界的泰斗Mike Stonebroker在一次技术交流中说:数据仓库和Hadoop所针对的场景重合型非常高,未来这两个市场一定会合并。
我们相信在数据仓库市场Hadoop会迟早替代到现在的产品,只不过,那时候的Hadoop已经又不是现在的样子了。就现在来讲,Hadoop还只是数据仓库产品的一个补充,和数据仓库一起构建混搭架构为上层应用联合提供服务。
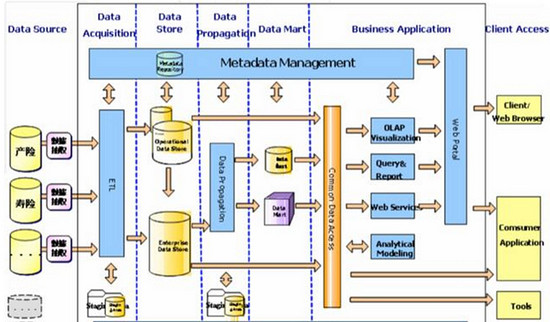
业务优化
在Hadoop上实现原来尚未实现的算法、应用,从原有的生产线中孵化出新的产品和业务,创造新的价值。通过新业务为企业带来新的市场和客户,从而增加企业收入。
Hadoop提供了强大的计算能力,专业大数据应用已经在几乎任何垂直领域都很出色,从银行业(反欺诈、征信等)、医疗保健(特别是在基因组学和药物研究),到零售业、服务业(个性化服务、智能服务,如UBer的自动派车功能等)。
在企业内部,各种工具已经出现,以帮助企业用户操作核心功能。例如,大数据通过大量的内部和外部的数据,实时更新数据,可以帮助销售和市场营销弄清楚哪些客户最有可能购买。客户服务应用可以帮助个性化服务; HR应用程序可帮助找出如何吸引和留住最优秀的员工等。
为什么Hadoop如此成功?这个问题似乎是个马后炮,但当我们今天惊叹于Hadoop在短短10年时间取得如此统治性地位的时候,确实会自然而然地思考为什么这一切会发生。基于与同期其他项目的比较,我们认为有很多因素的综合作用造就了这一奇迹:
技术架构:Hadoop推崇的本地化计算理念,其实现在可扩展性、可靠性上的优势,以及有弹性的多层级架构等都是领先其他产品而获得成功的内在因素。没有其他任何一个这样复杂的系统能快速的满足不断变化的用户需求。
硬件发展:摩尔定律为代表的scale up架构遇到了技术瓶颈,不断增加的计算需求迫使软件技术不得不转到分布式方向寻找解决方案。同时,PC服务器技术的发展使得像Hadoop这样使用廉价节点组群的技术变为可行,同时还具有很诱人的性价比优势。
工程验证:Google发表GFS和MapReduce论文时已经在内部有了可观的部署和实际的应用,而Hadoop在推向业界之前已经在Yahoo等互联网公司验证了工程上的可靠性和可用性,极大的增加了业界信心,从而迅速被接纳流行。而大量的部署实例又促进了Hadoop的发展喝成熟。
社区推动:Hadoop生态一直坚持开源开放,友好的Apache许可基本消除了厂商和用户的进入门槛,从而构建了有史以来最大最多样化最活跃的开发者社区,持续地推动着技术发展,让Hadoop超越了很多以前和同期的项目。
关注底层:Hadoop 的根基是打造一个分布式计算框架,让应用程序开发人员更容易的工作。业界持续推动的重点一直在不断夯实底层,并在诸如资源管理和安全领域等领域不断开花结果,为企业生产环境部署不断扫清障碍。
下一代分析平台
过去的十年中Apache Hadoop社区以疯狂的速度发展,现在俨然已经是事实上的大数据平台标准。但仍有更多的工作要做!大数据应用未来的价值在于预测,而预测的核心是分析。下一代的分析平台会是什么样呢?它必定会面临、同时也必须要解决以下的问题:
- 更多更快的数据。
- 更新的硬件特性及架构。
- 更高级的分析。
- 更安全。
因此,未来的几年,我们会继续见证“后Hadoop时代”的下一代企业大数据平台:
内存计算时代的来临。随着高级分析和实时应用的增长,对处理能力提出了更高的要求,数据处理重点从IO重新回到CPU。以内存计算为核心的Spark将代替以IO吞吐为核心的MapReduce成为分布式大数据处理的缺省通用引擎。做为既支持批处理有支持准实时流处理的通用引擎,Spark将能满足80%以上的应用场景。
然而,Spark毕竟核心还是批处理,擅长迭代式的计算,但并不能满足所有的应用场景。其他为特殊应用场景设计的工具会对其补充,包括:
OLAP。OLAP,尤其是聚合类的在线统计分析应用,对于数据的存储、组织和处理都和单纯离线批处理应用有很大不同。
知识发现。与传统应用解决已知问题不同,大数据的价值在于发现并解决未知问题。因此,要最大限度地发挥分析人员的智能,将数据检索变为数据探索。
统一数据访问管理。现在的数据访问由于数据存储的格式不同、位置不同,用户需要使用不同的接口、模型甚至语言。同时,不同的数据存储粒度都带来了在安全控制、管理治理上的诸多挑战。未来的趋势是将底层部署运维细节和上层业务开发进行隔离,因此,平台需要系统如下的功能保证:
安全。能够大数据平台上实现和传统数据管理系统中相同口径的数据管理安全策略,包括跨组件和工具的一体化的用户权利管理、细粒度访问控制、加解密和审计。
统一数据模型。通过抽象定义的数据描述,不仅可以统一管理数据模型、复用数据解析代码,还可以对于上层处理屏蔽底层存储的细节,从而实现开发/处理与运维/部署的解偶。
简化实时应用。现在用户不仅关心如何实时的收集数据,而且关心同时尽快的实现数据可见和分析结果上线。无论是以前的delta架构还是现在lambda架构等,都希望能够有一种解决快速数据的方案。Cloudera最新公开的Kudu虽然还没有进入产品发布,但却是现在解决这个问题可能的最佳方案:采用了使用单一平台简化了快速数据的“存取用”实现,是未来日志类数据分析的新的解决方案。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
超越RDBMS:数据仓库与数据湖、数据集市
现在企业从各种来源收集的大量数据已经远远超出传统关系学数据库可处理的范畴。这引发数据仓库与数据湖的问题:何时使 […]
-
对SAP HANA数据库涉嫌知识产权盗窃的指控存疑
Enterprise Applications Consultin公司负责人Joshua Greenbaum表 […]
-
数据货币将决定企业成败
在2017年3月McKinsey公司对500多名高管的调查显示,越来越多的企业使用数据和分析来推动增长,但目前 […]
-
在HANA上实施SAP BW要做哪些准备?
在HANA上实施SAP BW可以帮助公司利用到HANA的速度和性能优势。不过,CIO及技术团队首先要注意一些关键问题。